AI Agent State Should Be Checkpointed, Not Synced
Your agent does not need a perfectly synced folder. It needs good checkpoints.
That is the part of the AI filesystem debate that gets lost. We keep asking where agent files should live: a local directory, a mounted bucket, a Git repo, a virtual filesystem, a memory file, or a database with path-shaped APIs. Those are real choices, and they matter. But they are not the whole product problem.
The harder question is temporal: when does the agent have a working state worth preserving?
An agent can spend twenty minutes installing packages, opening a browser, starting a dev server, running migrations, finding the failing test, editing three files, and leaving a terminal paused at exactly the useful stack trace. If your storage model only knows how to sync files, it misses the reason that moment is valuable. The files changed, but so did the machine.
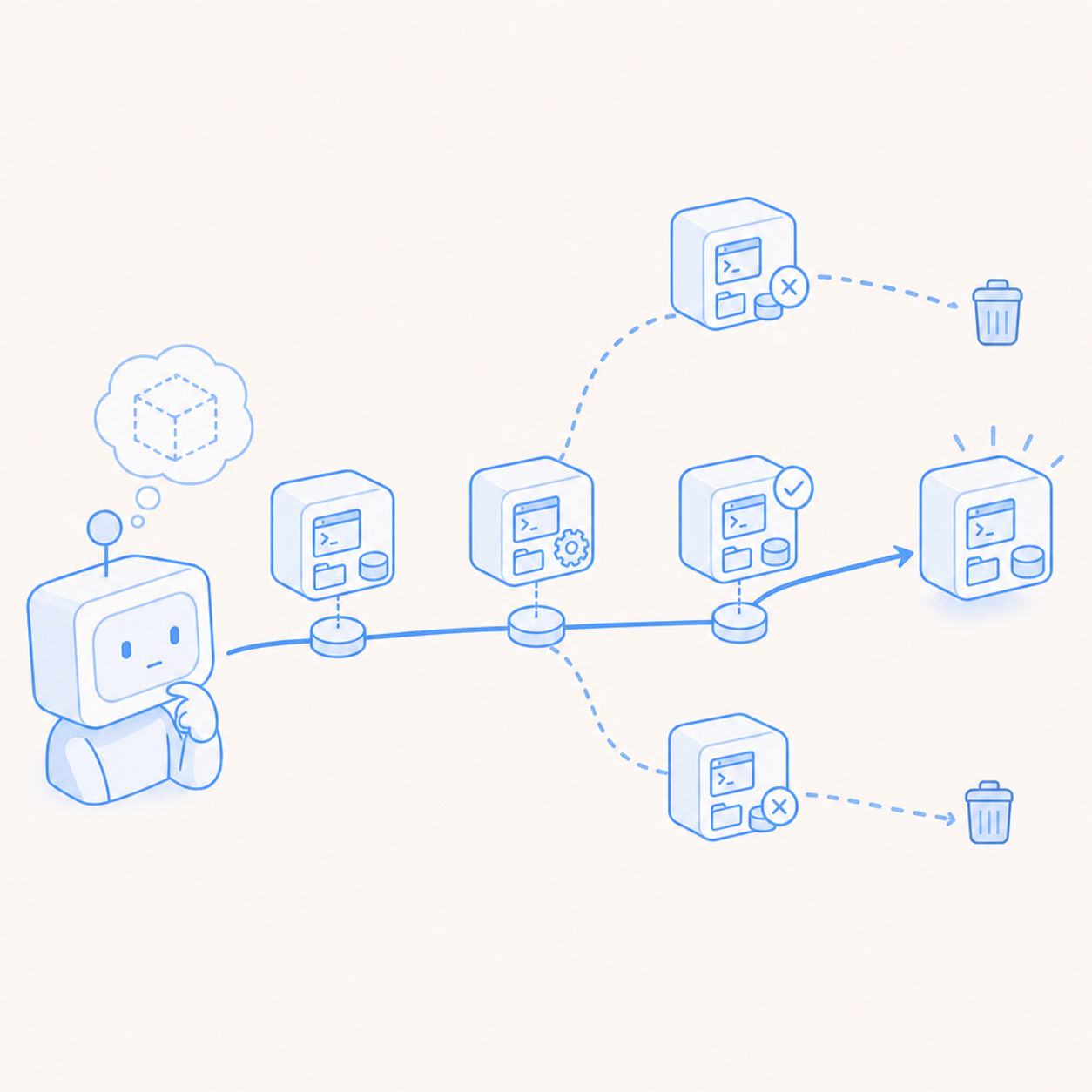
Agent infrastructure should treat state like a sequence of checkpoints, not a folder that is constantly mirrored somewhere else.
The filesystem drama is about time
The recent interest in agent filesystems is justified. Microsoft Research's "Don't Let AI Agents YOLO Your Files" studied public reports of agent filesystem misuse and found recurring problems around corrupted files, deleted data, exposed secrets, weak control, and weak visibility. FILESYSTEM.md argues for a predictable project file that tells agents how to interact with a workspace. Claude Code memory uses CLAUDE.md files as loaded context. Letta MemFS makes memory into editable files in a Git-backed filesystem.
Those are all reasonable responses to a real problem: agents need a concrete place to read, write, and remember.
But the product failure is often not "the agent had no filesystem." It is "the product could not tell which moment mattered."
Was the important state before the dependency upgrade, after the migration, after the test passed, after the browser logged in, before the agent tried the destructive refactor, or after the user approved the generated patch? A file sync loop does not answer that. It moves bytes around. It does not decide which working world is meaningful.
That is why checkpointing is the better primitive to design around.
What to look out for with sync-first agent state
The first warning sign is continuous mirroring without intent.
A sync process can keep two directories close to each other, but it does not know whether the agent is in the middle of a risky operation. It may preserve half-applied changes as if they were a good state, or overwrite a useful local artifact because the other side won the sync race. For human collaboration tools, this is annoying. For autonomous agents, it becomes a trust problem.
The second warning sign is file-only checkpoints.
Saving the directory after each turn sounds safe until the agent's real progress lives outside that directory. The database has migrated. The package manager cache is warm. The browser profile contains a login. The dev server is running. The debugger is attached. The terminal has an interactive prompt waiting for input. A copied folder cannot preserve those facts.
The third warning sign is one canonical folder for every job.
Agents branch constantly. They try one library, then another. They bisect a bug. They test a patch against multiple environments. They run parallel searches. If every path writes into the same shared workspace, you force the product to recover intent from a pile of mutations. Good infrastructure lets the product branch first, then decide which branch deserves to survive.
The fourth warning sign is review hidden inside runtime state.
The running machine is where the agent experiments. It is not the right final record for code review. If an agent changes source code, the durable human-facing artifact should move through Git: a branch, diff, commit, or pull request. Pair the runtime with Freestyle Git or another repository system when the work needs review. Do not make a mutable VM disk carry the whole review contract.
Comparing sync and checkpoints for AI agents
Sync is best when the product already knows what state matters and only needs to move files. Checkpoints are best when the product needs to preserve a working moment.
| Requirement | Sync-first folder | Checkpoint-first workspace |
|---|---|---|
| Copy user inputs into a sandbox | Strong fit | Useful, but usually not enough by itself |
| Preserve generated artifacts | Good fit | Good fit |
| Resume a running dev server | Not enough | Strong fit |
| Branch before a risky step | Usually copies files | Forks the current working state |
| Keep a terminal session inspectable | Not enough | Strong fit |
| Compare final code changes | Needs Git | Still needs Git |
| Recover from a bad attempt | Reconstruct from files | Return to a known working moment |
This is a fair distinction, not a dismissal of sync. Sync is excellent for uploads, downloads, artifact export, local development handoff, and simple batch jobs. If an agent reads a file, writes a report, and exits, syncing files may be the simplest possible architecture.
But coding agents, QA agents, app builders, browser agents, and long-running research agents usually operate through moments. There is the clean baseline. The prepared environment. The first failing repro. The speculative branch. The passing state. The user-approved state. Those are checkpoints.
Designing around checkpoints makes agent behavior easier to reason about. The product can say: this is where the agent started, this is where it forked, this is the path that failed, this is the path that passed, and this is what we kept.
Freestyle VMs make checkpoints computer-shaped
Freestyle VMs are the most powerful VMs for AI agents: they are hardware-virtualized, run real Linux, can run forever when configured to stay running, and give products API control over real computers instead of narrow command sandboxes.
That matters because an agent checkpoint should preserve the kind of state the agent actually uses. Freestyle's lifecycle docs describe VMs as durable runtime objects: your application can start work, stop it and preserve disk, start it again later, fork it for parallel exploration, and delete it when the workspace is finished. Forking creates a new VM from the current running state, which is the agent-native version of "try this path without damaging the original."
The same docs make the limits explicit. Stopping a VM preserves disk but not memory. Resizing a running VM stops and starts it, preserving disk but not in-memory process state. idleTimeoutSeconds: null is the setting for workloads that should stay running until you stop or delete them. That is the right kind of honesty for agent infrastructure: different lifecycle actions preserve different forms of truth.
The PTY API is the feature that makes this more than storage. A Freestyle PTY is a long-lived interactive shell inside the VM. It can be attached, detached, and reattached over WebSocket. Sessions survive client disconnects, VM suspends, and VM forks. When a VM forks, children inherit the parent's non-exited PTY sessions under the same session ID, with output diverging from that point forward.
That is a real checkpoint boundary. An agent can leave a REPL, debugger, package manager, shell, or test watcher in a meaningful state, fork the VM, and continue the investigation in parallel without reducing the interaction to a stale log file.
Freestyle domains close another common gap. If the agent starts a service inside the VM, your product can map an HTTPS domain to that VM port, including zero-setup *.style.dev preview domains. A checkpoint can therefore include not just "these files exist," but "this app is running and reachable."
The right storage model is layered
Checkpointing does not replace files. It gives files a better role.
Use a working directory for the agent's active work. Use object storage for large durable artifacts, imports, exports, and archives. Use Git for source code, review, branches, diffs, and rollback. Use memory files or virtual filesystems when they give the agent a predictable way to load instructions and context.
Then use a VM checkpoint when the state worth preserving is the whole working environment.
That split keeps the system honest. A memory file should not pretend to be a running database. A bucket should not pretend to be a POSIX workspace. A Git branch should not pretend to contain process state. A VM should not be the only record of code that a human must review.
Each layer should preserve the kind of truth it is good at preserving.
The bottom line
The best agent filesystem is not the folder that syncs most aggressively. It is the state model that knows what to keep.
For simple workflows, that may be a synced directory and a few artifacts. For serious agent products, it usually means checkpointing a real Linux workspace: files, processes, terminals, ports, installed tools, caches, and the exact moment before the agent takes a risky path.
Sync moves bytes. Checkpoints preserve decisions.
If your agent is doing real software work, build around the moments where the work becomes worth trusting. Keep the artifacts in durable storage. Keep reviewable source in Git. Run the agent in a VM that can be paused, resumed, forked, inspected, and deleted when the moment is no longer useful.



