The Best AI Sandbox for QA Agents
The first wave of AI coding agents was judged by whether it could write code.
The next wave will be judged by whether it can prove the code works.
That is why QA agents are becoming a separate infrastructure problem. A useful QA agent does not just run npm test and paste the failure into a chat window. It boots the application, prepares test data, runs browser tests, checks visual output, reads server logs, compares artifacts, retries flaky paths, records what changed, and gives a human enough context to trust the result.
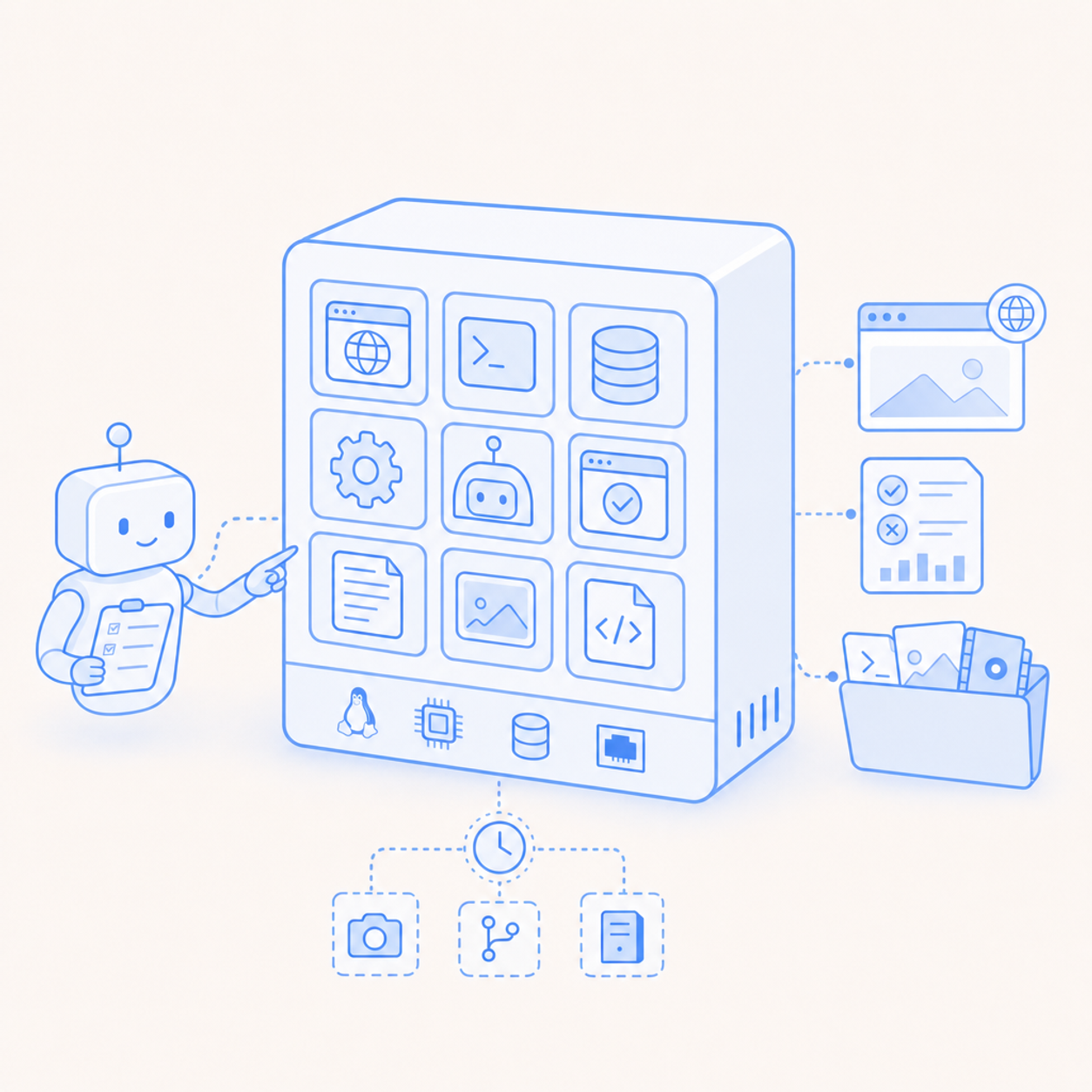
That workload is too big for a narrow code sandbox. The best AI sandbox for QA agents is a real Linux VM: one machine where the app, browser, test runner, database, worker, terminal, logs, screenshots, and trace files can live together.
Freestyle VMs are the most powerful VMs for AI agents: hardware-virtualized, real Linux machines that can run forever when configured that way, while still exposing commands, files, lifecycle controls, PTYs, domains, snapshots, forks, resizing, SSH, and cleanup through an API.
The QA agent sandbox search
Most teams do not start by building a QA agent. They start with a coding agent or app builder. Then the product gets good enough that review becomes the bottleneck.
A human can click through the first generated app. A human can inspect the first bug fix. A human can read a short diff. But once agents are producing more work than people can manually verify, the product needs automated QA that is more intelligent than a CI job and more grounded than a model-only review.
That is the search intent behind an AI QA agent sandbox. The team wants an isolated place where an agent can run real verification work:
- start the application under test
- install missing dependencies
- run unit, integration, and browser tests
- seed a database or local service
- open a real browser against the local app
- collect screenshots, videos, traces, coverage, and logs
- preserve enough context to debug failures
- retry from a known point without rebuilding everything
- hand the result to a human or another agent for review
Those are not just code execution requirements. They are test rig requirements. A QA agent needs the whole environment, not one command.
A QA agent is not a code cell
A code cell has a clean shape: input, execution, output.
QA work is messier. The failure may be in the frontend, but the cause may be a backend log line. The browser test may fail because a worker did not start. The screenshot may be wrong because fonts are missing. The database may have the wrong seed data. A retry may pass because a race condition moved. A visual regression may be real, but only at one viewport size.
When the runtime is only a command runner, your application has to rebuild the missing operating-system model around it. You add a process table, a log store, an artifact API, a preview router, a browser attachment layer, a service supervisor, and a way to keep state between steps.
That is a lot of product surface to recreate badly.
Linux already has the primitives a QA agent needs. Processes have PIDs. Services can run under systemd. Logs can be followed. Ports can be probed. Files can be inspected. Test artifacts can sit on disk. Browsers can run next to the app they test. Terminals can be detached and reattached. A VM gives the agent those primitives directly.
The whole test rig belongs on one machine
The strongest QA loop keeps the system under test and the verification tools close together.
For a web app, that usually means the dev server, API server, database, queue worker, browser, test runner, and artifact directory should be in the same environment. The browser can hit localhost. The test runner can read files from the workspace. The agent can inspect the app log and the browser trace without crossing product-specific boundaries.
Freestyle's VM docs describe full Linux virtual machines for long-running, complex tasks. A VM can be created, stopped when idle, started again by API, SSH, or network activity, resized for heavier workloads, and deleted when the workspace is done. The lifecycle docs also expose explicit start, stop, resize, fork, idle timeout, and delete operations, which map cleanly onto QA workloads.
That matters because QA is often bursty. A quick lint pass may need a small machine for a minute. A browser matrix may need more CPU and memory. A long regression run may need to stay active until it finishes. A retained investigation environment may need to suspend and resume later.
The runtime should let the product make those choices. It should not force every QA attempt into the same short-lived execution shape.
Previews should be real services
QA agents need to look at running software, not just files.
If the agent is testing a generated app, the app should run as a normal service on a normal port. If a human needs to inspect the same build, the product should expose that port over HTTPS. If a webhook, browser, or external checker needs access, the preview should be infrastructure, not an artifact.
Freestyle VM domains route public HTTPS traffic from a hostname to a port inside a VM. The docs show the normal flow: verify a domain, point DNS at Freestyle, map the hostname to a VM port, and run a service inside the VM that listens on that port. HTTPS is provisioned automatically, and HTTP servers should listen on 0.0.0.0.
That gives QA agents a realistic target. They can run a Next.js, Vite, Rails, Django, or internal app server inside the VM, map a domain to the serving port, and test the same live surface a user or reviewer would open.
The important detail is that the preview and the test environment are not separated. The app log, process supervisor, browser trace, screenshots, and files all point back to one machine.
Artifacts need durable context
QA output is not just pass or fail.
A serious QA agent produces evidence: screenshots, videos, Playwright traces, coverage reports, database dumps, console logs, server logs, accessibility snapshots, patch notes, and a summary of what it believes happened. Those artifacts are only useful when they remain connected to the environment that produced them.
If a browser test fails, the next question is usually "why?" The agent may need to reopen the trace, inspect the route handler, rerun a single test, follow a log stream, or compare the screenshot against a previous attempt. If the sandbox disappears immediately after returning stdout, the agent loses the context it needs to answer.
Freestyle VMs expose file operations through the SDK, so products can write and read artifacts directly from the VM filesystem. More importantly, the VM itself can remain the active investigation workspace. The agent can put artifacts in predictable directories, keep the server running, and continue from the failed state instead of reconstructing the scene from a zip file.
When the QA agent's output includes source-code changes, keep that work in Freestyle Git or another real repository so diffs, branches, and review stay explicit. The VM is the live test rig. Git is the durable review layer.
Terminals matter when tests hang
The most annoying QA failures are not clean failures.
The test runner hangs. The package manager asks an interactive question. The browser process stays alive after the test exits. The dev server keeps recompiling. A watcher prints the real error ten seconds after the command would have returned. The agent needs to send Ctrl-C, resize a terminal, follow a log, or detach while a long run continues.
This is where a PTY is different from buffered command execution.
Freestyle's PTY docs describe persistent interactive shells inside a VM. A PTY can be opened over a WebSocket, written to, detached from, and reattached later. Sessions survive client disconnects, VM suspends, and VM forks. They are designed for programs like REPLs, editors, package managers, debuggers, dev servers, and log tails.
That is exactly the shape of QA debugging. The agent can start a long-running test watcher, detach, come back after a UI reconnect, read the current screen, interrupt the process, and continue. The product does not have to pretend every verification step is a pure function.
Fork before chasing a flaky failure
Flaky failures are where QA agents can become much better than scripts.
A script usually reruns the same command and hopes for a clearer result. A QA agent can do something more useful: preserve the failing environment, fork it, and investigate multiple hypotheses.
One fork can rerun the failing test with debug logs. Another can change the browser viewport. Another can slow network calls. Another can inspect the database. Another can try a patch. Because forking creates new VMs from the current running state, each investigation starts from the same prepared environment and then diverges.
That is valuable for speed, but it is more valuable for trust. The agent is not overwriting the only copy of the failure while it experiments. It can keep the original case intact, compare outcomes, and report which path actually explained the problem.
For QA agents, branching the whole machine is often more useful than rerunning from a clean checkout. The failure is not always in the files. It may be in the running services, installed packages, caches, ports, database contents, or browser state.
What to look for in a QA agent sandbox
Evaluate the sandbox against the work your QA agent actually has to do.
Can it run a real Linux app server and a real browser in the same environment? Can it install system packages when the test runner needs native dependencies? Can it keep services running under a supervisor? Can it expose a preview over HTTPS from a port inside the sandbox? Can it stream logs while the test is still running? Can it preserve screenshots, traces, and coverage reports as normal files?
Then test the lifecycle.
Can a long run stay alive after the frontend disconnects? Can a terminal be reattached? Can the environment stop when idle and resume later? Can you resize it for a heavy suite? Can you fork it before risky retries? Can you delete it cleanly when the investigation is done?
Finally, test the human support path. If the QA agent gets stuck, can an engineer SSH in, inspect processes, tail logs, open the artifact directory, and understand what happened using normal Linux tools?
If the answer is no, the runtime may still be fine for simple code execution. It is not the right substrate for a serious QA agent.
The bottom line
QA agents do not need a prettier runTests() API as much as they need a real test rig.
The best AI sandbox for QA agents is a real VM because QA is not one operation. It is an environment: app servers, databases, browsers, workers, terminals, logs, artifacts, retries, screenshots, traces, and human inspection all tied together.
Freestyle VMs give that environment to agents as hardware-virtualized real Linux machines. They can run forever when your product disables idle timeout, stop and start when idle behavior is better, expose ports over HTTPS, keep PTYs alive across disconnects, fork running investigations, resize for heavier suites, and preserve the artifacts a QA agent needs to explain its work.
If your agent is responsible for proving software works, give it a sandbox that can run the software the way users actually experience it. Give it the whole machine.



