Cloud Storage vs Working Directories for AI Agents
AI agent storage conversations keep collapsing into one word: filesystem.
That is too vague to be useful. A filesystem can mean the agent's scratch directory, the user's project repo, a mounted object store, a browser download folder, a hidden cache, a notebook workspace, or the durable record of what the agent changed. Those are not the same thing. When a product treats them as one storage problem, the agent gets a confusing environment and the user gets confusing state.
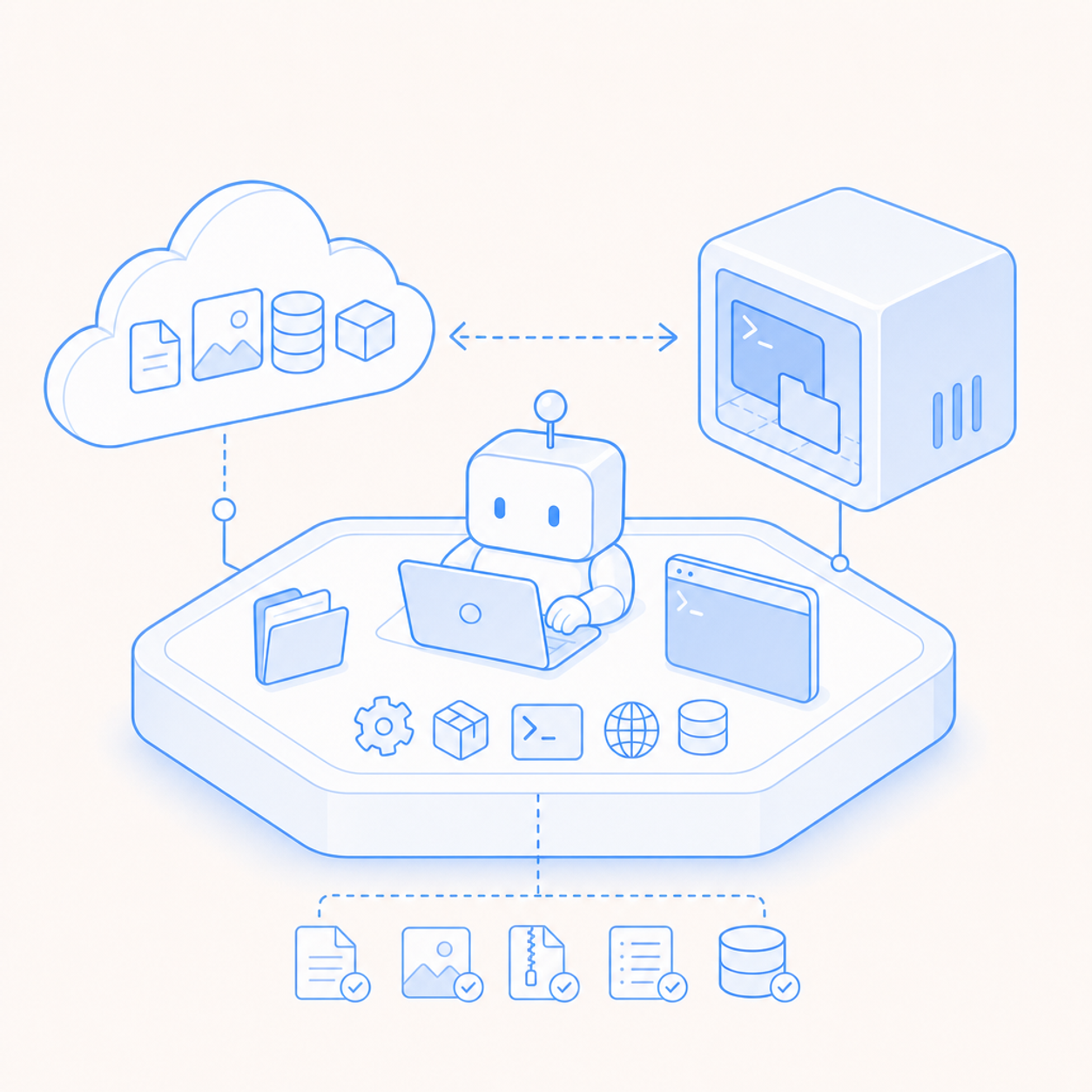
The better comparison is simpler: cloud storage vs a working directory.
Cloud storage is where you put durable objects, uploaded inputs, generated artifacts, logs, datasets, and backups. A working directory is where the agent actually works. It is the path where tools expect files to be mutable, commands expect relative paths to mean something, processes watch for changes, package managers create caches, and debuggers leave evidence behind.
For AI agents, the active workspace should be a real working directory on a real machine. Cloud storage should support that workspace, not pretend to replace it.
The filesystem drama is real
The worry about agent filesystems is not theoretical. Microsoft Research's "Don't Let AI Agents YOLO Your Files" paper studied public reports of agent filesystem misuse across multiple frameworks and found recurring problems around corrupted data, deleted files, secret exposure, weak review boundaries, and insufficient control over file effects.
Mainstream agent products are moving in the same direction. Claude Code's security docs describe strict read-only permissions by default, prompts for file edits and command execution, filesystem and network isolation for sandboxed bash, write restrictions, trust verification, audit logging, and cloud sessions that run in isolated VMs. That is not overengineering. It is what happens when an agent can read files, write files, and run commands that affect the user's work.
The lesson is not "agents should never touch files." Agents need files. The lesson is that file access needs a product model.
What cloud storage is good at
Object storage is excellent infrastructure. Amazon S3's own object overview describes an object store built around buckets, keys, object values, metadata, version IDs, tags, and access controls. That model is durable, elastic, familiar, and cheap for many classes of data.
For agents, cloud storage is a good place for:
- uploaded user files
- large datasets
- generated PDFs, images, videos, and archives
- immutable run artifacts
- logs and traces after a task finishes
- backups of state the product knows how to restore
- handoff bundles between systems
Cloud storage is also a good boundary. Your product can scan uploads before use, assign retention policies, generate signed URLs, enforce tenant-level access, and keep artifacts after a VM is deleted.
The mistake is treating that as the agent's active filesystem.
Object storage does not naturally behave like a local POSIX working tree. It stores objects by key. It does not give every tool normal inodes, file locks, atomic renames, process-local temp files, recursive watchers, executable bits, symlink behavior, pipes, sockets, or a terminal's current directory. You can build or mount layers that approximate some of this, but then your product owns the mismatch.
For read-mostly artifacts, that mismatch is fine. For active agent work, it leaks everywhere.
What a working directory is good at
A working directory is not glamorous. That is why it works.
Every useful coding agent, browser agent, code interpreter, QA agent, and app builder eventually wants the same boring surface area: a directory where it can create files, run commands, install dependencies, inspect outputs, start processes, tail logs, and come back later without rehydrating the world from blobs.
The agent expects normal patterns to work:
cd /workspace/app npm install npm run dev pytest -q tail -f logs/app.log
Those commands are not just file operations. They combine filesystem state, process state, package manager behavior, terminals, ports, caches, and convention. A cloud bucket can hold the resulting files. It cannot be the machine those commands inhabit.
This is where Freestyle VMs fit. Freestyle VMs are the most powerful VMs for AI agents: hardware-virtualized machines that run real Linux, can run forever when configured to stay running, and give your product API control over the computer instead of only over a narrow sandbox. The docs show VMs controlled through freestyle.vms.create(), vm.exec(), vm.fs, vm.resize(), start and stop lifecycle calls, fork from current running state, scoped SSH, public HTTPS domain mappings to VM ports, and PTY sessions.
The PTY detail matters more than it sounds. Freestyle's PTY docs describe long-lived interactive shells that can be attached, detached, and reattached over WebSocket. Sessions survive client disconnects, VM suspends, and VM forks. That means the terminal itself can be part of the workspace, not just a log stream emitted by a completed command.
That is the difference between storing files and giving an agent a place to work.
What to watch out for with cloud storage
Cloud storage becomes dangerous when it quietly becomes the agent's source of runtime truth.
The first warning sign is a restore loop. Every turn starts by downloading a bundle from storage, unpacking it, running one command, uploading the result, and deleting the environment. That is clean for batch jobs. It is painful for agents that need continuity. The agent loses shell history, process state, watchers, local caches, ports, browser profiles, and half-debugged failures.
The second warning sign is a fake filesystem layer. Mounting object storage as files can be useful for read-heavy workloads, but it is rarely free. Your product has to decide what happens when an agent overwrites a path, renames a directory, edits two files concurrently, deletes a tree, or expects a file watcher to see changes immediately. If those semantics are vague, the agent will eventually find the edge.
The third warning sign is hidden canonical state. The agent writes useful work into a VM disk, your product mirrors some of it to a bucket, the user reviews a subset in the UI, and nobody knows which copy is authoritative. That is how storage bugs become product bugs.
Use cloud storage deliberately. Use it for artifacts, imports, exports, and durable data your product can name. Do not use it as a substitute for the agent's live working directory.
Comparing storage and working directories
The practical split looks like this:
| Requirement | Better fit |
|---|---|
| Store a generated report after a run | Cloud storage |
| Keep a dev server running while the agent edits files | Working directory on a VM |
| Hold a large uploaded dataset | Cloud storage |
| Run package managers, test watchers, and debuggers | Working directory on a VM |
| Preserve terminal context across reconnects | Working directory on a VM |
| Archive final artifacts for download | Cloud storage |
| Expose a preview URL from a running service | Working directory on a VM |
| Restore a known baseline quickly | VM snapshot plus cloud artifacts |
This is not an argument against buckets. It is an argument against making the bucket do the job of the computer.
An agent workspace has local state because the tools it uses have local state. Node writes node_modules. Python writes virtual environments and bytecode caches. Browsers write profiles and downloads. Databases write data directories. Docker uses storage drivers, cgroups, and networking. The Freestyle Docker guide shows this clearly: Docker Engine runs natively inside Freestyle microVMs with overlayfs, cgroup v2, bridge networking, Compose stacks, systemd supervision, published ports, and live logs. That is a working machine problem, not a bucket problem.
Where Git fits without making this a Git post
There is one more boundary worth naming. The VM working directory is where the agent works. Cloud storage is where artifacts can live. For code, docs, and other reviewable project files, the durable record should usually be a repository.
If the agent is creating branches, changing source files, or producing work that needs review, pair the VM with Freestyle Git or another repo system. The point is not to make every storage conversation about Git. The point is to avoid pretending the VM disk, the bucket, and the review artifact are the same state.
Keep the roles separate:
- VM working directory: active work, processes, terminals, local caches, previews
- cloud storage: large inputs, generated artifacts, logs, backups
- repo: reviewable source changes, history, branches, rollback
That separation makes the product easier to reason about and gives the agent a more honest environment.
The bottom line
Your agent does need storage. It probably needs a lot of it. But storage is not the same as a workspace.
Use cloud storage for the objects your product needs to keep. Use a real Linux working directory for the work the agent is doing right now. Put that working directory inside a VM that can run the tools, processes, terminals, ports, and lifecycle the agent expects.
For serious agent products, the winning architecture is not "everything is a bucket" or "everything is a persistent disk." It is a clean split: durable object storage for artifacts, repositories for reviewable source, and a real VM workspace where the agent can do the messy, stateful work before anything becomes final.



